The DAA File Format
In diary entry "Malicious .DAA Attachments", we extracted a malicious executable from a Direct Access Archive file.
Let's take a closer look at this file format. Here is an hex/ascii dump of the beginning of the file:
.png)
With the source code of DAA2ISO, I was able to make some sense of this data. I highlighted important parts:
- First we have the magic sequence: DAA...
- Second, we have an offset (0x0000004C) to the list of compressed chunk lengths
- Third, we have the file format version: 0x00000100
- Fourth, we have an offset (0x0000005E) to the first compressed chunk
- And then we have the list of chunk lengths (position 0x0000004C)
- And the chunks themselves (position 0x0000005E)
The list of compressed chunk lengths is a bit special: each lenght value is encoded with 3 bytes, using neither big-endian nor little-endian format.
The number format is the following: hex value 697 is encoded as 00 97 06. So first you have the most significant byte, then the least significant byte, and then the remaining, middle byte.
Together with the pointer to the first compressed chunk (position 0x0000005E), we can use this length list to calculate the offsets of the other compressed chunks.
Example: the second chunk is located at 0x5E + 0x697 = 0x06F3. DAA version 0x100 uses zlib compression (DEFLATE), and the compressed data is stored without header.
Armed with this information, I could write a Python script to extract and decompress the chunks stored inside a DAA file.
However, I wrote a different program. For quite some time, I was playing with the idea to write a program that can detect compressed data inside a binary stream. Since a DAA file is essentially a concatenation of zlib compressed chunks, such a program should also be able to extract and decompress the ISO file inside a DAA file.
Here is the result of my beta program running on the DAA sample:
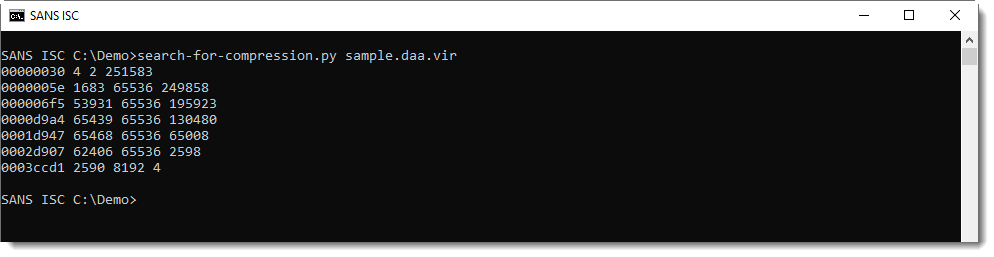
Each line represents compressed data found by the tool. The columns are:
- start position of compressed data (hexadecimal)
- size of the compressed data (decimal)
- size of the decompressed data (decimal)
- size of the remaining data (decimal)
This generic method will also generate false positives: data that decompresses but is not actual compressed data. Like the first line: it's very small (4 bytes compressed, 2 bytes decompressed) and is actually inside the DAA header. So this is clearly a false positive.
Option -n can be used to impose a minimum length on the compressed data. This can be used to filter out some false positives:
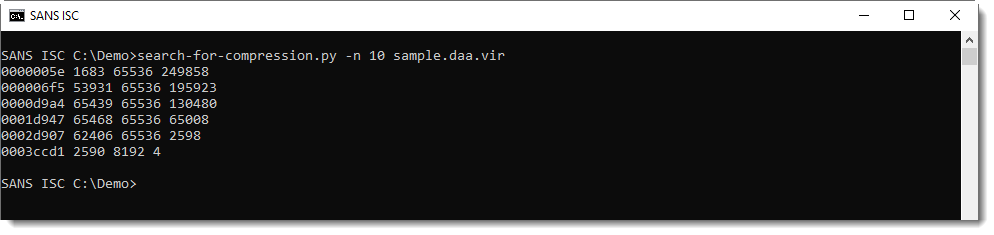
Remark that the first byte sequence of compressed data is found at position 0x5E, the same position as mentioned in the header.
And the second byte sequence of compressed data is found at position 0x6F5, that's the position that we calculated with the length of the first chunk.
All decompressed chunks have a size of 65536, except the last chunk: that's how the DAA format stores the embedded ISO file. It's chopped-up in chunks of 65536 each, that are then compressed.
Finally, I can use option -d to decompress and concatenate all compressed chunks:

A similar file format is also used for other CD/DVD image formats, like the gBurner format, compressed ISO format, ...
Didier Stevens
Senior handler
Microsoft MVP
blog.DidierStevens.com DidierStevensLabs.com

Comments