Method For String Extraction Filtering
In diary entry "XLSB Files: Because Binary is Stealthier Than XML", Xavier shows how to extract strings (URLs) from binary files that make up an Excel spreadsheet.
This inspired me to make a tool to parse this XLSB file format: "Quickie: Parsing XLSB Documents".
Now I'm presenting another method, one that uses string analysis. String analysis is a simple (malware) analysis technique: one uses a tool like strings to extract printable strings from binary files, and then reviews the list of extracted strings for interesting info. Like URLs. But the list of extracted strings is often huge, and it can be difficult to find relevant info (or impossible, if the strings are encoded/encrypted).
Performing string analysis is easy, one does not need to know about the internal format of the analyzed binary files. But you need a bit of luck: the strings need to be readable. And you need to find them inside a long lists of strings, of which many are irrelevant.
Now I created another tool, that can assist with string analysis: myjson-filter.py.
Let's go back to the maldoc sample Xavier analyzed, and use my tools zipdump.py and strings.py to extract all strings.
We can't just run the strings command on the XLSB file, because this is an OOXML file: a ZIP container containing XML and binary files. So we need to extract each file from the zip container and run the strings command on it.
One way to do this with my tools, is as follows:
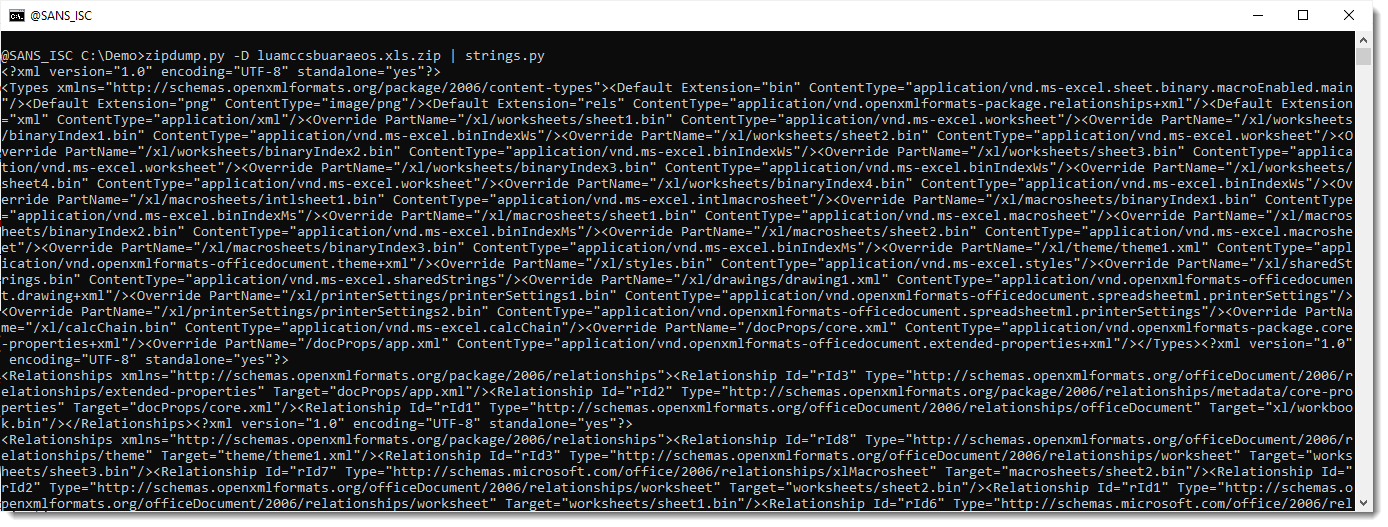
Option -D extracts all files from the ZIP container and sends their content to stdout, which is then read by strings.py to extract strings.
The problem here, is that there are a lot of strings: that's because the OOXML file also contains XML files, that are text files.
So it would be better, if we could extract strings only from binary files, excluding XML files.
That's what we can do with my new tool.
First we will switch to a JSON format I designed into some of my tools, like zipdump.py and strings.py.
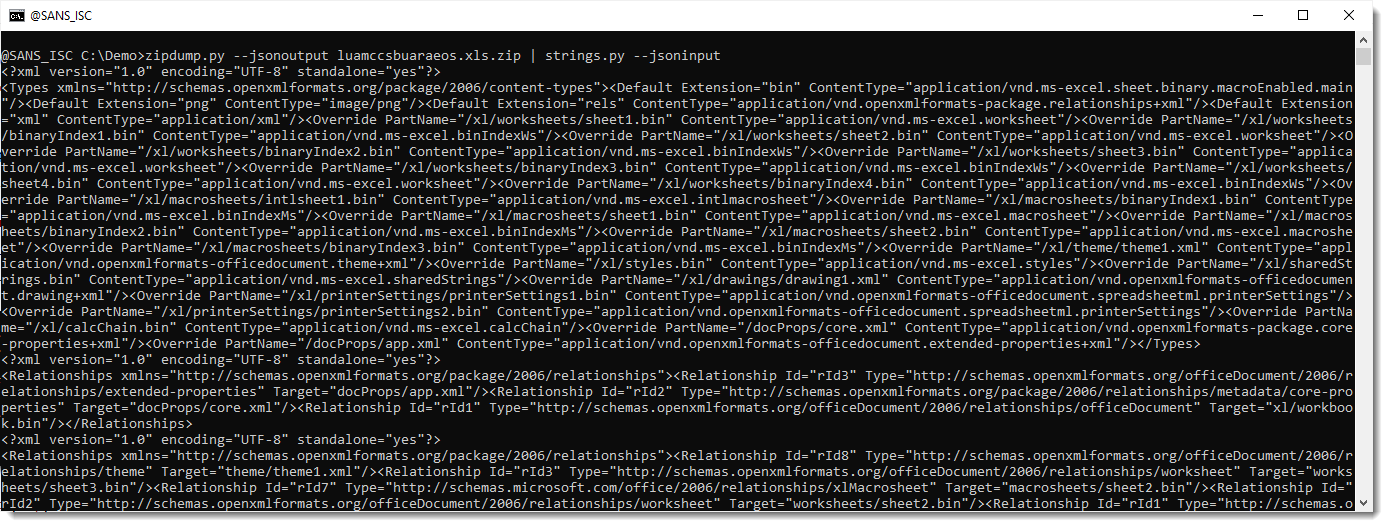
Options --jsonoutput makes zipdump.py produce JSON output (with the content of all files) and --jsoninput makes strings.py consume JSON input.
The result is the same, as with the -D option. But since we are dealing with structured JSON data now, instead of one binary stream of file contents, we can manipulate that JSON data before it is consumed by strings.
And that is what one can do with my new tool myjson-filter.py.
We will use this tool to filter out all XML files, so that strings.py processes only the remaining files (which should all be binary files).
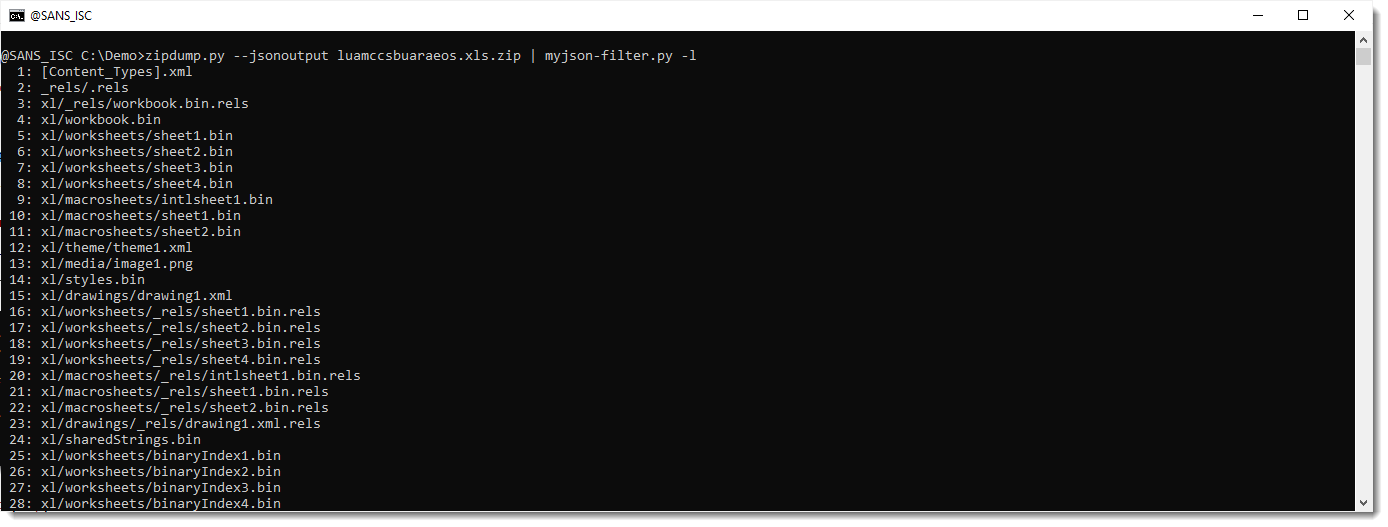
To understand how myjson-filter.py works, we will start by using the -l option. This option directs myjson-filter.py to produce a list of the items it has filtered, in stead of producing filtered JSON data.
Here is the output:
Now we will start to filter, by using option -c. Option -c takes a regular expression, and selects all items that match that regular expression. We use regular expression ^<\?xml to match all content that starts (^) with <?xml. Since ? is a meta character in regular expression syntax, we need to escape it like this: \?
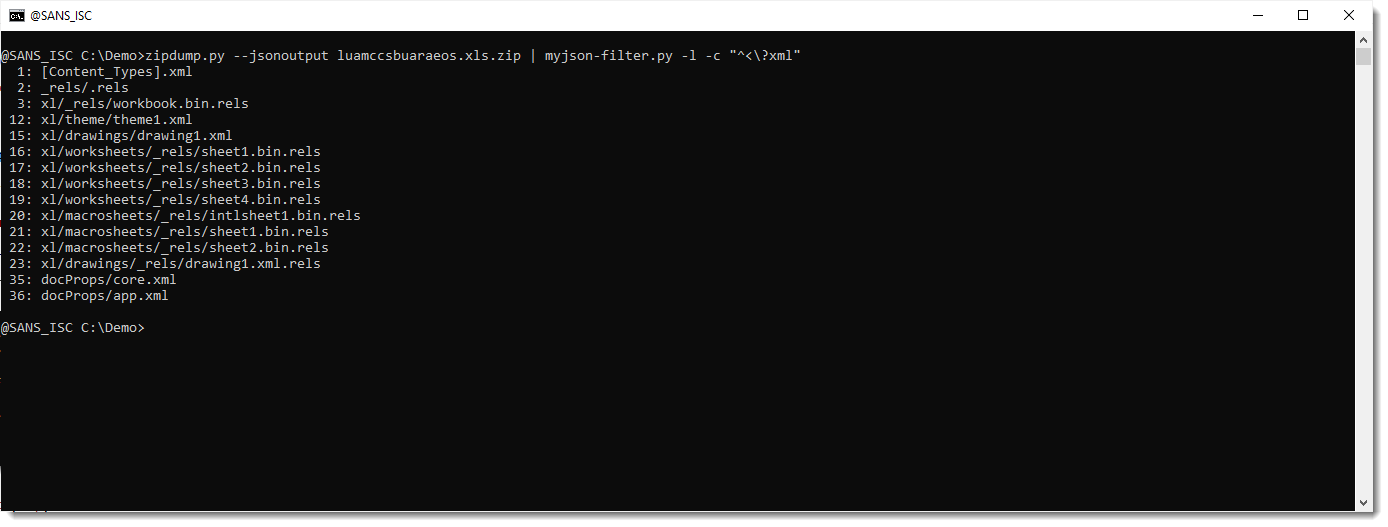
Now we have selected all XML files. But what we want, is to select all files that are not XML files: we need to invert the selection. This can be done by prefixing the regular expression with #v# (this syntax is particular to my tool, it's not part of the regular expression syntax). v is a flag to invert the selection (like option -v for grep).
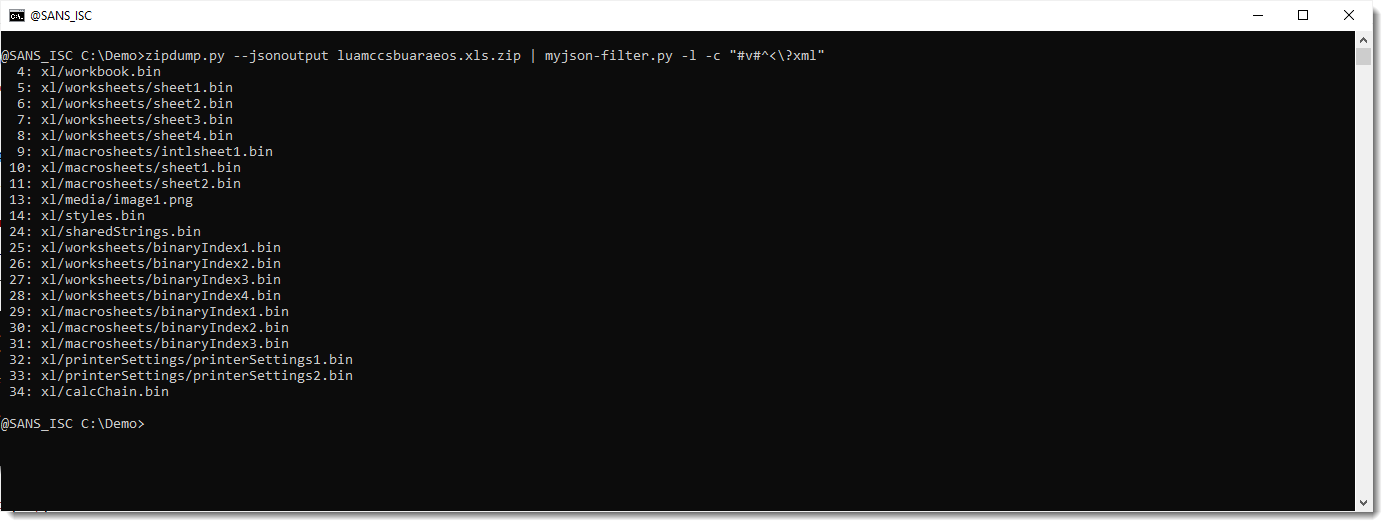
And once we see that the selected files are the ones we desire, we can drop option -l, so that myjson-filter.py produces filtered JSON data that can be passed on to strings.py.
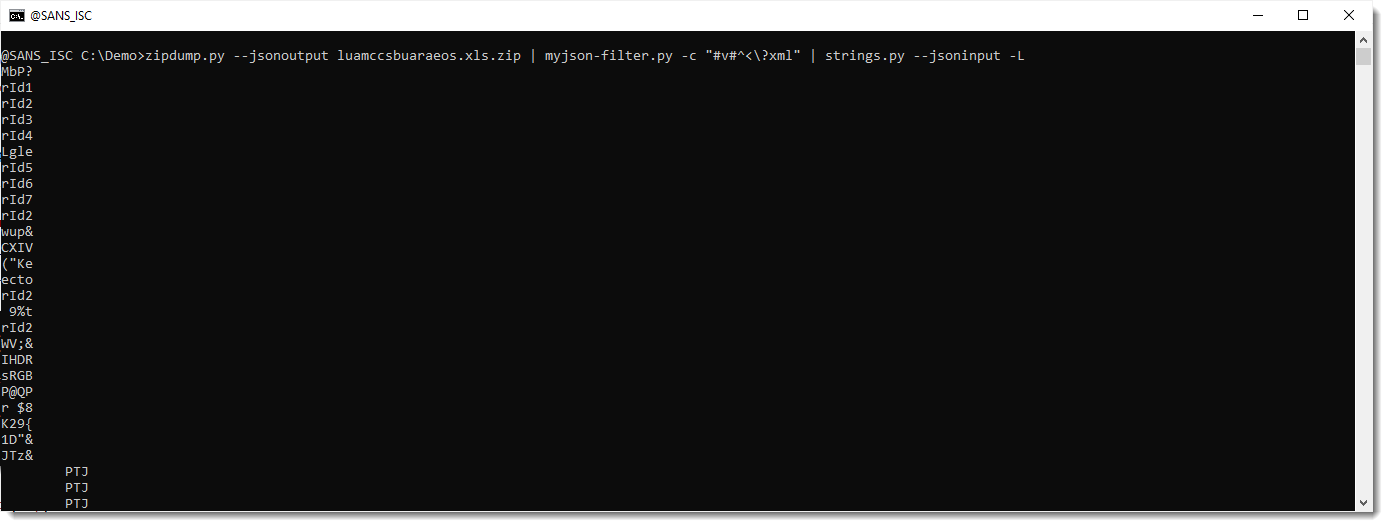
I am using option -L to sort the strings by length, so that the longest strings are at the end of the output:
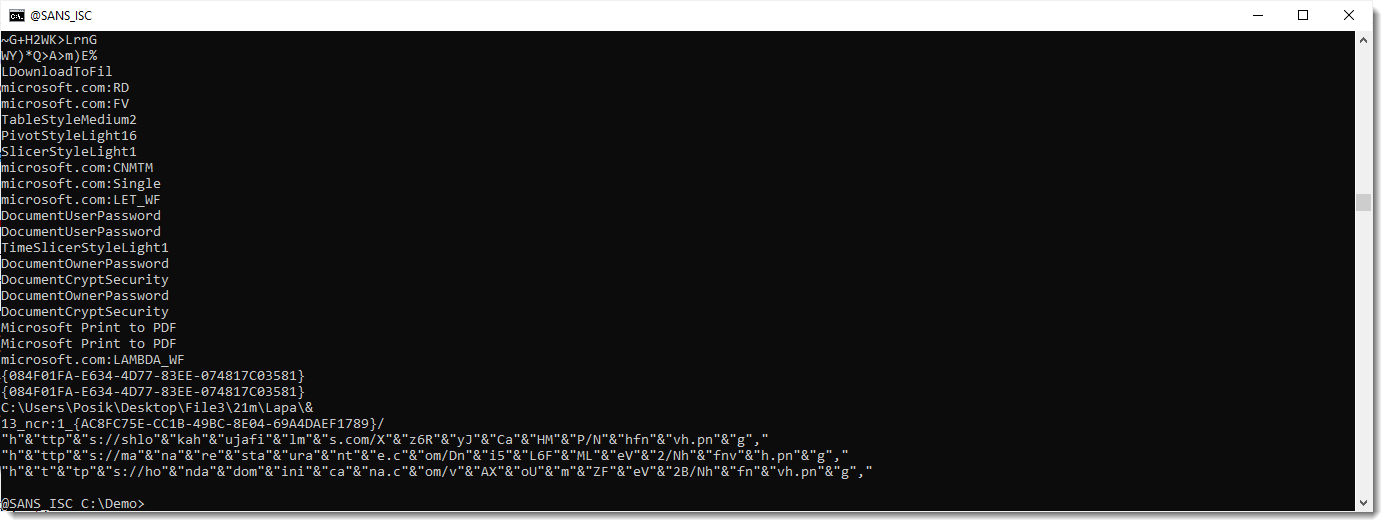
At the end, we see 3 long strings that look like obfuscated URLs. They are indeed expressions, that concatenate small strings together into one string. We filter them out by selecting only strings that are 50 characters long or more (-n 50):

And finally, we undo the string contatenation (& operator) by remove "&" with sed:

Without any knowledge of the XLSB file format, we were still able to extract the URLs from this maldoc.
Didier Stevens
Senior handler
Microsoft MVP
blog.DidierStevens.com


Comments