
Extracting the text from PDF documents
In my previous diary entry, we looked at a phishing PDF and extracted the URLs.
But what if you want to look at the message contained in the PDF without opening it? There are several tools (online and offline) that can convert PDF documents to text.
It can also be done with my pdf-parser.py tool, but we need to know a bit of PDF internals.
First we search for objects that are pages:
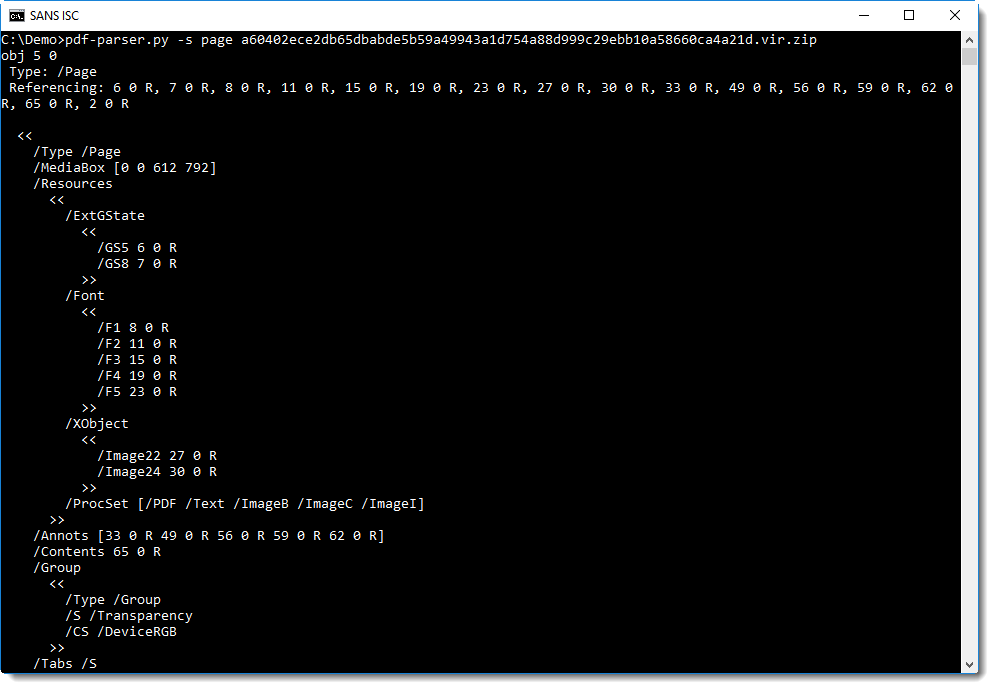
Object 5 is a page, and the content of the page is in object 65 (/Contents 65 0 R).
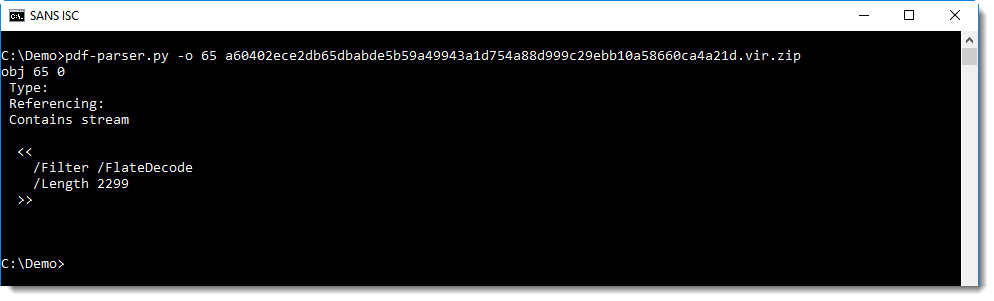
It contains a compressed stream, let's decompress it:
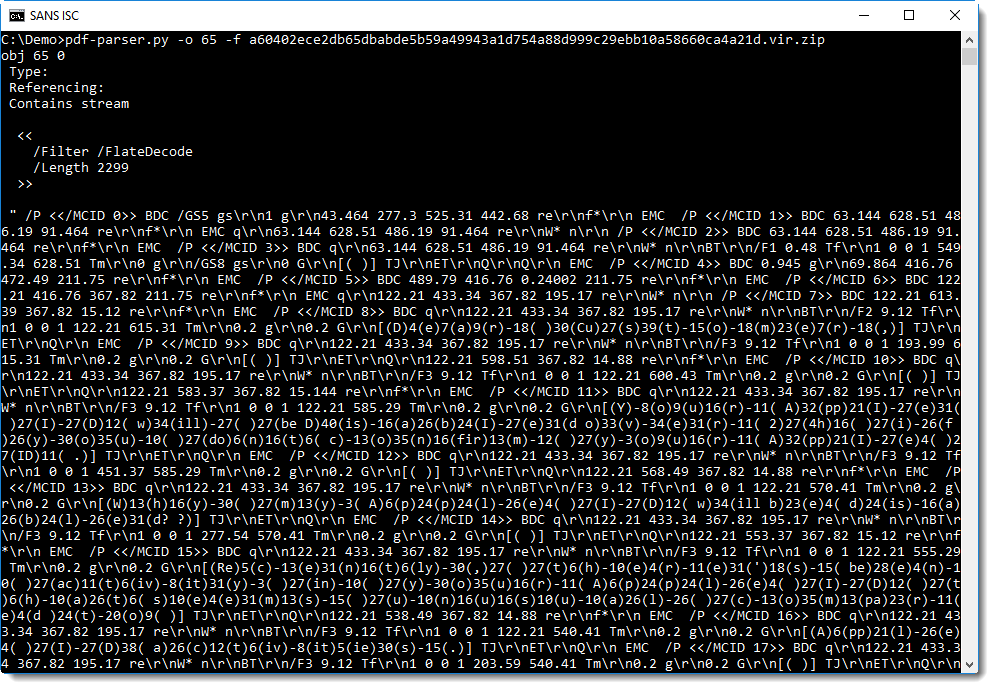
Text can be rendered on a PDF page using "text-showing operators" like Tj and TJ. Tj takes a string as argument, and TJ a list of strings and integers. If you take a close look at the screenshot above, you will find the TJ operator preceded by a list of strings. It's not that easy to see though, so let's grep for TJ:
A list is represented with square brackets [], and a string with parentheses ().
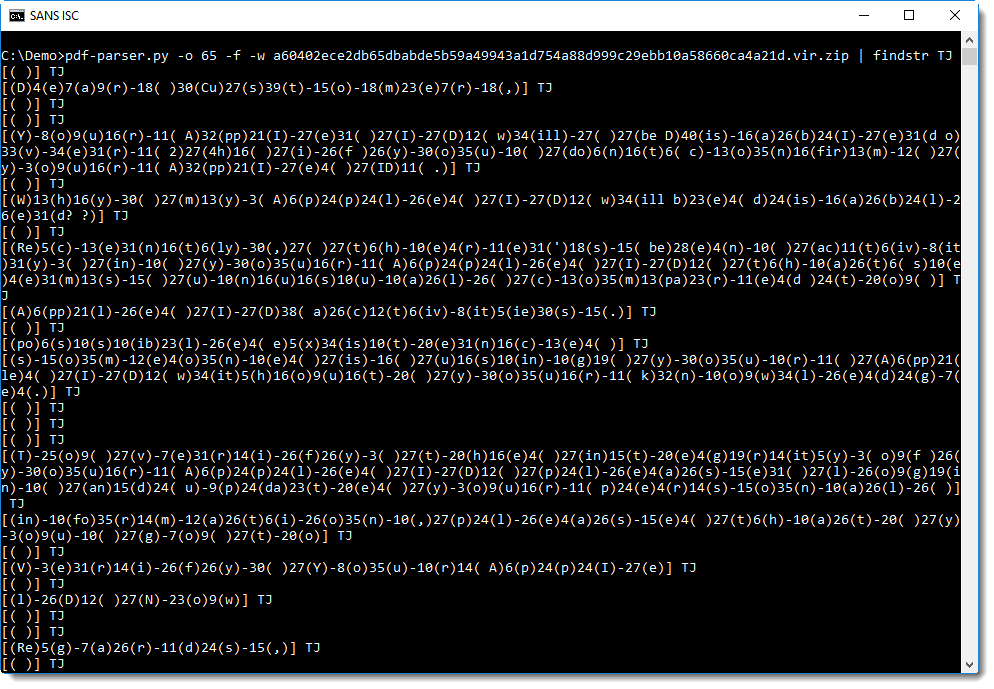
[( )] TJ instructs the PDF reader to draw a space character on the page. This is a postfix language: the operands are placed before the operator. [( )] is the operand and TJ is the operator. [( )] is a list of strings, containing just one string ( ).
[(D)4(e)7(a)9(r)-18( )30(Cu)27(s)39(t)-15(o)-18(m)23(e)7(r)-18(,)] TJ instructs the PDF reader to draw a text "Dear Customer," on the page. Each letter is found inside a string () in this list, and the integers indicate the amount of space to leave between each letter.
If we extract all the letters from the strings and concatenate them, we can extract the text:
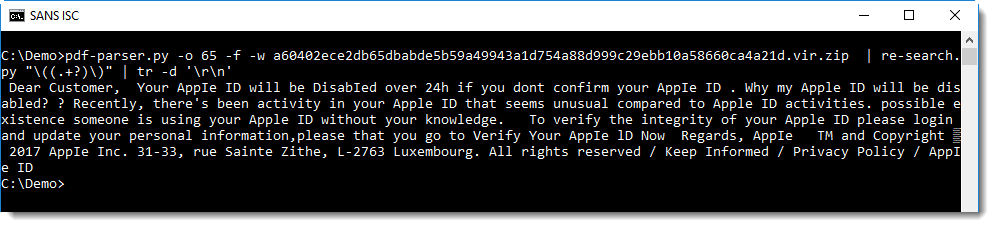
Using regular expression \(.+?\) we can select all strings, but we want the content of the string, not the string itself. We can achieve this with my re-search.py tool and regular expression \((.+?)\). re-search.py searches through (text) files using a regular expression, and outputs all matches. If you define a capture group () inside a regular expression, then re-search will output the content of the capture group, and not the complete match.
This will output each character on a line, and we use tr to remove all newlines and thus join all characters in one big line.
This method is not practical of course, it's only to be used if automatic conversion tools can not be used.
Didier Stevens
Microsoft MVP Consumer Security
blog.DidierStevens.com DidierStevensLabs.com


Comments
Anonymous
Nov 6th 2017
7 years ago