[Guest Diary] 7 minutes and 4 steps to a quick win: A write-up on custom tools
by Justin Leibach, SANS BACS Student (Version: 1)
[This is a Guest Diary by Justin Leibach, an ISC intern as a part of the SANS.edu BACS [1] degree program]
The web logs from my DShield [2] honeypot always produce the most interesting information. I enjoy being “on keyboard” and using command line tools to view, sort, filter and manipulate the .json files, it is weirdly satisfying. Pounding away on my mechanical keyboard is effective for a single log file, but when I started to zoom out a bit and began looking at multiple days, weeks, even months of information, it became clear there must be a better way.
If you are busy, and need a TLDR, here it is: My GitHub [3]
Log files combined: 31
Lines of JSON parsed: 163,510,310
Countries of origin: 76
Script running time: 7 minutes
Steps from start to finish: 4
My outputs from running the scripts:
 |
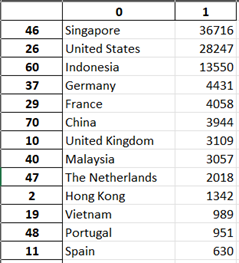 |
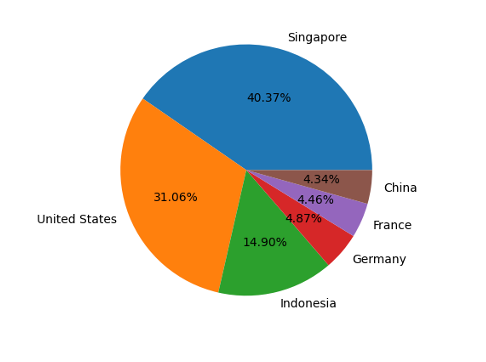
| Figure 1: Python .png output depicts percentage of the Top 6 countries of Source IP to interact with honeypot. Percentage is based on 6 countries rather than the entire 76 country dataset. | Figure 2: Snippet from Python output to excel showing the top 13 countries in descending order. |
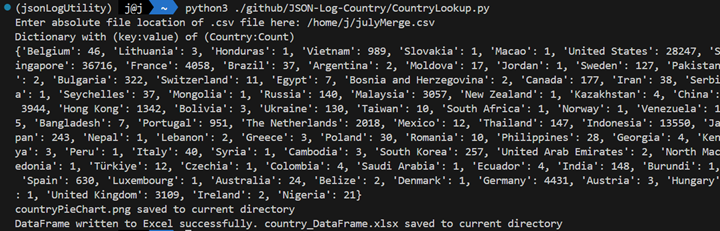
Figure 3: Screenshot capturing running the script and the printed output of a Python Dictionary holding all countries and occurrences.
The endgame
Before I started solving the problem, I needed to define it:
I want to know what countries are probing my honeypot the most, over time, to develop a better threat intelligence picture.
Here are the major things I thought I needed to do:
| Step | Description | Initial Tool Attempt | Final Tool Used |
|---|---|---|---|
| 1 | Combine JSON Files | Python | BASH |
| 2 | Filter JSON Files | Python | BASH |
| 3 | Search a database of WHOIS, return country name | Python | Python |
| 4 | Produce graphics for quick analysis | Python | Python |
Ideally, it is also a tool that is highly portable and easily modified for other users, even a very new analyst.
My Toolbox
 |
vs. | 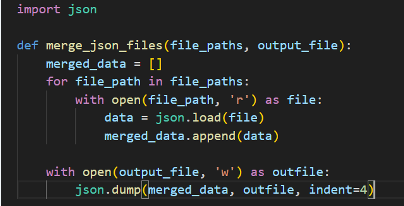 |
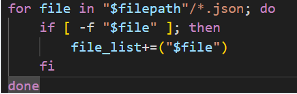
| Figure 4: Sample BASH snippet for combining JSON files. | Figure 5: Sample Python code snippet for combining JSON files. |
To solve this problem, I knew I wanted to use Python, but sometimes Bash proves the more elegant solution.
Python:
- Combine the files: Small files are no problem, but larger files and datasets could not be processed.
- Memory errors abound! No matter my angle of approach, I kept receiving the
killed (program exited with code: 137), a memory error. - PATHLIB was just not working for me. Dealing with POSIX paths seemed unwieldy for my approach, and code was quickly becoming very non-pythonic.
- OS module wasn’t suitable for my use case, as it would potentially exclude use for Windows users.
- Memory errors abound! No matter my angle of approach, I kept receiving the
- Filter the files: Like my attempt at combining files, small sets worked to some extent but created memory errors for larger files.
- Search a WHOIS IP database: Python was the obvious choice here to find the country of origin.
- I used a localized database downloaded from a free service and the
geoip2.databasemodule. - An API could be used in Python to produce similar results.
- I used a localized database downloaded from a free service and the
- Produce graphics: Python is a language used for data science, so another natural choice.
- For the pie chart I used the
matplotlibandpillowsmodule - To create the dataframe and excel document I used the
pandasandiomodules.
- For the pie chart I used the
Bourne Again Shell (BASH):
BASH scripting is highly portable, and surprisingly powerful. It is usable on any *NIX machine, MACOS, or Windows with either WSL or a terminal emulator like Git Bash.
- Combine the files:
- Still crashing due to memory issues when only using
jq - Settled on iterating through them, requiring a quick refresher on BASH “
for” loops.
- Still crashing due to memory issues when only using
- Filter the files: Straightforward *NIX tools were able to do this.
Moral of the story here: Use the right tool for the job.
Combine JSON Files
The script I used to combine the files can be found at GitHub [4].
It takes two user inputs.
- Filepath: This is a folder with all the web logs you want to combine.
- Filename: This is what you want it to be named.
The script creates an array with all the file paths, then iterates through that array using the jq utility to append to a single file. The real work in the code is happening here:
#!/bin/bash
# Debugging output to check the contents of file_list
echo "Files in file_list:"
for f in "${file_list[@]}"; do
echo "$f"
done
echo "This may take a while"
# iterate through each file in the file list array and combine it into a single json file using jq.
for file in "${file_list[@]}"; do
jq -s '.' $file >> $temp
done
# command to remove the all arrays in the JSON file. Necessary to properly filter with jq
cat $temp | jq '.[]' > $filename
Filter JSON Files
Through much trial and error, I found that the best way for python to look through the information was to give it a .csv file. So, I created two BASH scripts to do just that.
The first script filters everything and outputs a .csv file, the only problem with this was the sheer amount of Amazon Web Services (AWS) interactions with my AWS hosted honeypot on AWS LightSail. The second script is an improvement, and more versatile for use in any environment. You can run either.
- Filter all can be found at GitHub [5]
- Filtering to exclude IP’s input by user can be found at GitHub [6]
The second script is a bit more complex. It takes an input of IP addresses and assigns them to a variable. Then the hard part, using sed to search and edit, then using jq to filter and tr to transform that output before finally writing to a user designated filename in the current directory. The bulk of the work in the code is here:
# from user input, create variable called $filepath
echo -n "Enter absolute path to JSON file to create new csv for source ip: "
read jsonfilepath
# from user input, create variable called $filename to be used later in writing final merged file
echo -n "What do you want you want your new JSON file to be called (please add .csv)?: "
read csvfilename
# from user inpute, create a variable to exclude ip addresses from the CSV.
# In my case I will exclude any IP address associated with Amazon services, as I am using an AWS honeypot as my source
# Example jq for figuring out top offenders that you would likely exclude: cat Merged.json| jq '.sip' | sort | uniq -c | sort
echo -n "Enter all IP addresses you wish to exclude here, separated by a space: "
echo -e "\nExample: 192.168.1.1 192.168.1.2 192.168.1.3"
read IP_Addresses
# Convert the IP addresses into a jq filter
jq_filter=$(printf 'select(.sip and (%s)) | [.sip] | @csv' "$(echo $IP_Addresses | sed 's/ /" and .sip != "/g' | sed 's/^/.sip != "/' | sed 's/$/"/')")
# Apply the jq filter to the JSON data and format the output
echo "This will take a little while"
cat $jsonfilepath | jq -r "$jq_filter" | tr ',' '\n' > $csvfilename
echo "$csvfilename created in current directory"
Use Python to Search a Database of WHOIS, returning Country name
My original thought was to use an API for country lookups. This could provide valuable information for use in reporting, and there are numerous services that offer this to varying degrees.
One of those is https://ipgeolocation.io/ [7]. This seemed like the right choice. They have a free lookup, for up to 30k requests per month. But then I went back to my endgame…it wasn’t portable enough.
So instead I went with something I learned about in my SEC 573 SANS Class [8] authored by Mark Bagget; The geiop2 python module supported by MAXMIND, and the GEOIP local database. There are a few options on configuration, and it does require a free account. Follow these instructions (and my script) for easy setup: https://dev.maxmind.com/geoip/updating-databases [9].
Importantly, it requires some “C” extensions to be installed to greatly increase the performance of database lookups. This is a suitable time to introduce the setup script that can help initial setup. It can be found GitHub [10].
This is the BASH script (with liberal comments):
#! /bin/bash
# Script to set up system with required dependencies
sudo add-apt-repository ppa:maxmind/ppa
sudo apt update
# this installs a "C" extension to increase performance of database lookups
sudo apt install libmaxminddb0 libmaxminddb-dev mmdb-bin
# Consider installing all of this in a VENV (virtual Environment) if running certain distros of linux.
sudo apt install python3-pip
sudo apt update
python3 -m pip install numpy geoip2 pandas openpyxl pillow
#### follow instructions here: https://dev.maxmind.com/geoip/geolocate-an-ip/databases/#1-install-the-geoip2-client-library ####
sudo apt install geoipupdate
###create free account @ https://www.maxmind.com/en/geolite2/signup ###
: 'follow instructions in email
- follow instructions here: https://dev.maxmind.com/geoip/updating-databases
- can set up cronjob
- to run had to designate the config file when running:'
#### sudo geoipupdate -f /usr/local/etc/GeoIP.conf -v ####
Use Python to produce graphics for quick analysis
The script itself can be found GitHub [11].
This python script takes input from the user for the location of the .csv file and uses functions to: open the file, create a one-time reader for the geoip database, strip the .csv files, lookup countries in the database, create a list of countries, count the countries in the list, remove duplicate countries adding to a list, create a dictionary of “Country:Count”, take input for “N” amount for the most common countries, create a pie chart of the “N” amount, export the pie chart as .png, create a dataframe from dictionary data, write dataframe to Excel.
This script requires these libraries, installed in the setup script via PIP:
- numpy
- geoip2
- pandas
- openpyxl
- pillow
The script itself has liberal comments with the hope that any user can edit for bespoke use.
To change the number of countries used for percentage calculation and subsequent labeling in the pie-chart, simply edit the script at the “N” number found at line 64:
# return top N value in the dict
def top_countries(data_dict):
n = 6
counter = Counter(data_dict)
top_n_countries = dict(counter.most_common(n))
return top_n_countries
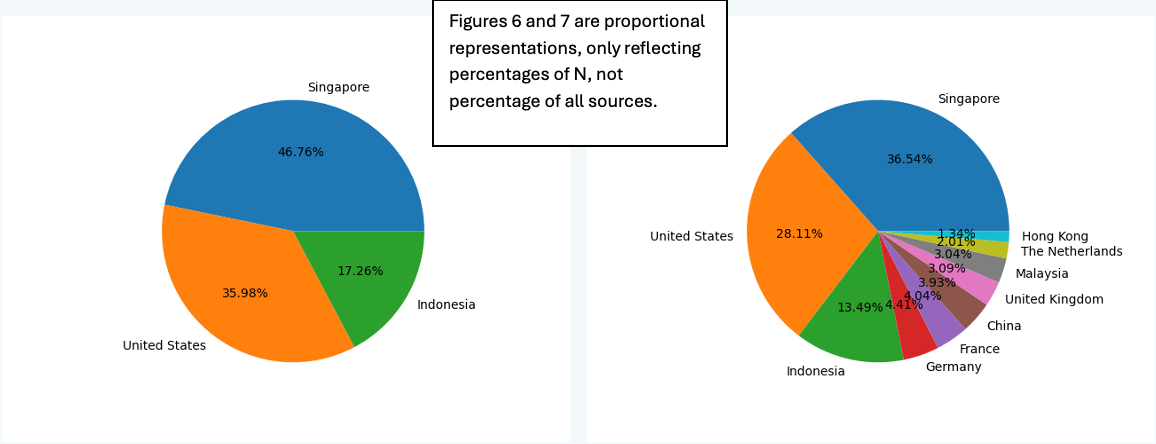 |
|
| Figure 6: N changed to 3 | Figure 7: N changed to 10. |
4 Simple Steps
This is the linear path from start to finish (also outlined in GitHub Readme File [12] ):
- Link to BASH setup script [10] – Run time: ~ 30 seconds
- This script is designed for Debian based Linux Distros. Users on MACOS or other Linux Distributions must amend script for package tools and package archives.
- Link to BASH combine JSON script [4] – Run time: 5 minutes
- Link to BASH filter-with-exclude-IPs and export .csv script [5] or filter-no-exclude [6] – Run time: 1 minute
- Link to Python script for lookup and export [11] - Run time: ~ 30 seconds
*Times based on my system files and will vary based on file sizes, internet connection and system configuration
Future Improvements
The tools described above met their original goal, but there is always room for improvements. Finding country of origin is great, but what if I want to know more?
- The BASH filtering script could be improved to output more files and datapoints like URL, user-agent, time, status codes, or the source IP addresses.
- These new output files could easily be inputs to an improved Python script to output similar charts and excel outputs of singular or combined datapoints without even needing to access an API or database.
- A process could be included to do reverse DNS lookups of the IP addresses to discover possible VPN usage.
But why?
As is, this tool can easily be paired with a single, or multiple honeypots set up in an enterprise environment to gather data and inform decision makers in your organization.
In a small, under-resourced, restrictive or immature organization, this free and open-source tool could be a quick win for a blue-teamer to improve the threat intelligence picture and bolster enterprise security through improved Firewall rules and IP address range blacklisting.
I hope this is helpful, and happy defending!
References and links:
[1] https://www.sans.edu/cyber-security-programs/bachelors-degree/
[2] https://github.com/DShield-ISC
[3] https://github.com/justin-leibach/JSON-Log-Country
[4] https://github.com/justin-leibach/JSON-Log-Country/blob/main/combine-JSON.sh
[5] https://github.com/justin-leibach/JSON-Log-Country/blob/main/filter.sh
[6] https://github.com/justin-leibach/JSON-Log-Country/blob/main/filter-with-exclude.sh
[7] https://ipgeolocation.io/
[8] https://www.sans.org/cyber-security-courses/automating-information-security-with-python/
[9] https://dev.maxmind.com/geoip/updating-databases
[10] https://github.com/justin-leibach/JSON-Log-Country/blob/main/setup.sh
[11] https://github.com/justin-leibach/JSON-Log-Country/blob/main/CountryLookup.py
[12] https://github.com/justin-leibach/JSON-Log-Country/blob/main/README.md
--
Jesse La Grew
Handler


Comments